단일 페이지 어플리케이션의
웹 크롤링 (https://blog.naver.com/yoojchul/221333353523)
에 소개된 방법 대로 페이스북도 읽을 수 있습니다. 아래 프로그램은 환경운동연합의 페이스북 글과 그 글에 달린 ‘좋아요’,
‘댓글’ , ‘공유’의 횟수를 가져 옵니다.

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | # -*- coding: utf-8 -*- from selenium import webdriver import time from bs4 import BeautifulSoup import sys fp = webdriver.FirefoxProfile("C:/Users/rcjcyoo/AppData/Roaming/Mozilla/Firefox/Profiles/y07d4b26.selenium") driver = webdriver.Firefox(fp) # keckodriver in the same directory with this script driver.implicitly_wait(3) driver.get('https://www.facebook.com') driver.find_element_by_xpath("//input[@name='email']").send_keys('xxxxx@xxxx.com') driver.find_element_by_xpath("//input[@name='pass']").send_keys('xxxxxx') login = driver.find_element_by_xpath("//input[@value='로그인']") login.click() driver.get('https://www.facebook.com/kfem.or.kr/') last_height = driver.execute_script("return document.body.scrollHeight") count = 0 while True: driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") count += 1 time.sleep(3) # Calculate new scroll height and compare with last scroll height new_height = driver.execute_script("return document.body.scrollHeight") if new_height == last_height or count > 3: break last_height = new_height non_bmp_map = dict.fromkeys(range(0x10000, sys.maxunicode + 1), 0xfffd) soup = BeautifulSoup(driver.page_source, 'html.parser') wrappers = soup.findAll("div", {"class":"_5pcr userContentWrapper"}) for w in wrappers: cnt = w.find("div", {"class":"_5pbx userContent _3576"}).find("p").text try: print(cnt.translate(non_bmp_map)) except UnicodeEncodeError: print("**unknown char**") attaches = w.findAll("div", {"class" : "_36_q"}) for a in attaches: print(a.text) print() |
라인 7과 8은 selenium를 통해 firefox를 실행하는 과정입니다. 실행에 프로필을 포함하는데 그 이유는 페이스북 접속시에 나타나는 귀찮은 firefox 알림창을 막기 위함입니다. 위 프로그램 실행 전에 “firefox.exe –p”로 firefox 프로필 관리자를 실행하고 “프로필 만들기”를 클릭해서 “selenium”를 만듭니다. 프로그램에서 사용할 때는 프로필 디렉토리 이름을 지정해야 하는데 보통 <home 디렉톨>/AppData/Roaming/Mozilla/Firefox/Profiles/xxxxx.selenium입니다.

해당 프로필로 firefox를 실행후 주소창에서 “about:config”을 입력하고 dom.push.enabled와 dom.webnotifications.enabled를 false로 바꿉니다. selenium를 통해 firefox를 실행할 때 프로필을 만들지 않으면 설정은 남아 있지 않고 항상 초기화 상태입니다.

라인 12과 13에서 아이디와 암호를 넣고 라인 15와 16에서 로그인
버튼을 클릭합니다. 라인 18로 환경운동연합 페이스북으로 넘어 갑니다.
라인 20부터 31까지는 반복적인 화면 스크롤 다운과 같은 역활을 합니다. 라인 20과 28은 페이스북 화면 y축 길이를 가져 오고 라인 23은
그 길이 만큼 스크롤 다운합니다. 다시 화면 y축 길이를 가져 와서
예전 길이가 같은 때, 즉 더 이상 화면이 내려가지 않을 때 루프에서 빠져 나와 스크롤 다운을 중단합니다. 스크롤 다운 횟수가 4 이상이 되어도 중단합니다. 라인 25에서 스크롤
다운과 길이를 가져 오는 사이에 3초를 쉽니다. 쉬는 시간이 짧으면 웹브라우저의 느린 스크롤 다운 반응으로
인해 y축 길이가 같은 경우가 생겨
끝이 아닌데도 불구하고 의도하지 않게 루프가 끝날 수가 있습니다.
페이스북에서 글과 ‘좋아요’
횟수를 찾을 때는 beautifulsoup 패키지를 이용합니다. 라인 35에서 BeautifulSoup 첫번째 인수가 driver.page_source인데 이것이 웹브라우저에
뿌려진 DOM 데이터입니다.
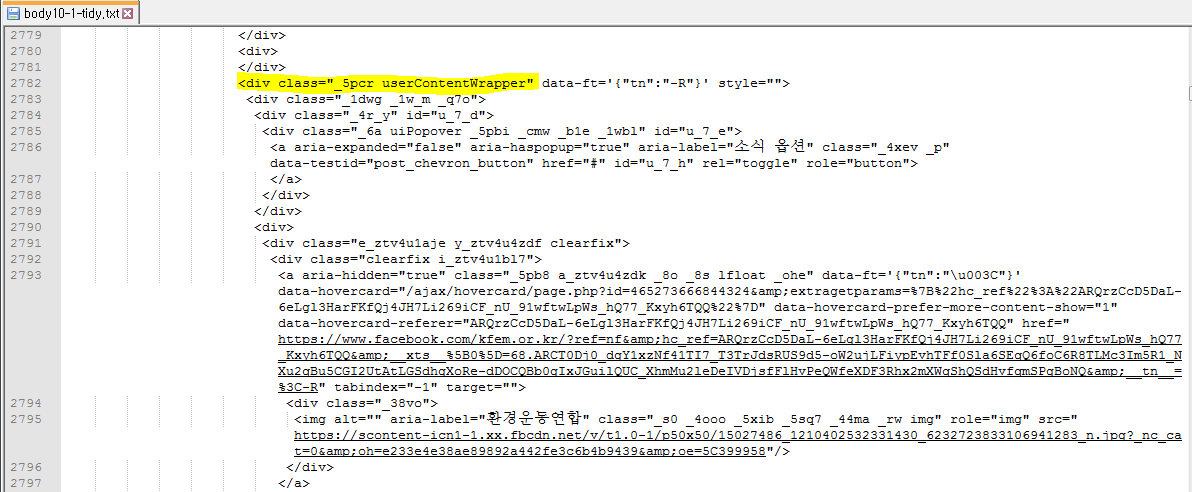
게시글과 ‘좋아요’는 div 태그에 둘러 쌓있는데 먼저 클래스 이름 “_5pcr
userContentWrapper”된 wrapper가 있습니다. wrapper
안에 게시글과 ‘좋아요’ 을 이끄는 다른 div태그가 있으므로 프로그램에서
“_5pcr userContentWrapper”를 찾습니다. 이름이 특이한데 별도로 soup.prettify()로 출력한 아래 그림에서 확인합니다.
게시글은 div태그에
클래스 이름은 "_5pbx userContent _3576”인데 이 역시 미리
soup.prettify() 결과에서 확인합니다.

‘좋아요’는 div 태그에 클래스 이름은 "_36_q"입니다. ‘좋아요’ 외에 같은
class 이름으로 ‘댓글’과
‘공유’가 있습니다.

이러한 태그와 클래스 이름을 근거로
라인 39가 47까지 게시글과 ‘좋아요’ 횟수를 찾을 수 있습니다. 클래스 이름은 2018년 9월 4일 기준이고 이후 달라질 수 있습니다. 게시글 출력시에 특수 문자로 인해 간혹
UnicodeEncoderError이 발생합니다. 출력하기 전에 translate(non_bmp_map)으로 0x10000이상의 코드는 0xfff0로 변환해서
에러가 발생하지 않도록 합니다.
아래 그림은 프로그램 결과로서 게시글과
함께 게시글의 ‘좋아요’ 횟수를 표시합니다.

댓글 없음:
댓글 쓰기