카카오스토리에 올려진 글을 얻기 위한
크롤링 과정을 소개합니다. 카카오스토리 2018년 8월 13일 기준이고 이후 카카오스토리가 개편되면 도움이 되지 못합니다.
www.kakaostory.com으로 접속하면 로그인 화면인 https://accounts.kakao.com/login/kakaostory로 넘어갑니다. 주로 이메일로 하는 아이디와 비밀번호가 핵심이고 로그인 버튼이
있습니다.
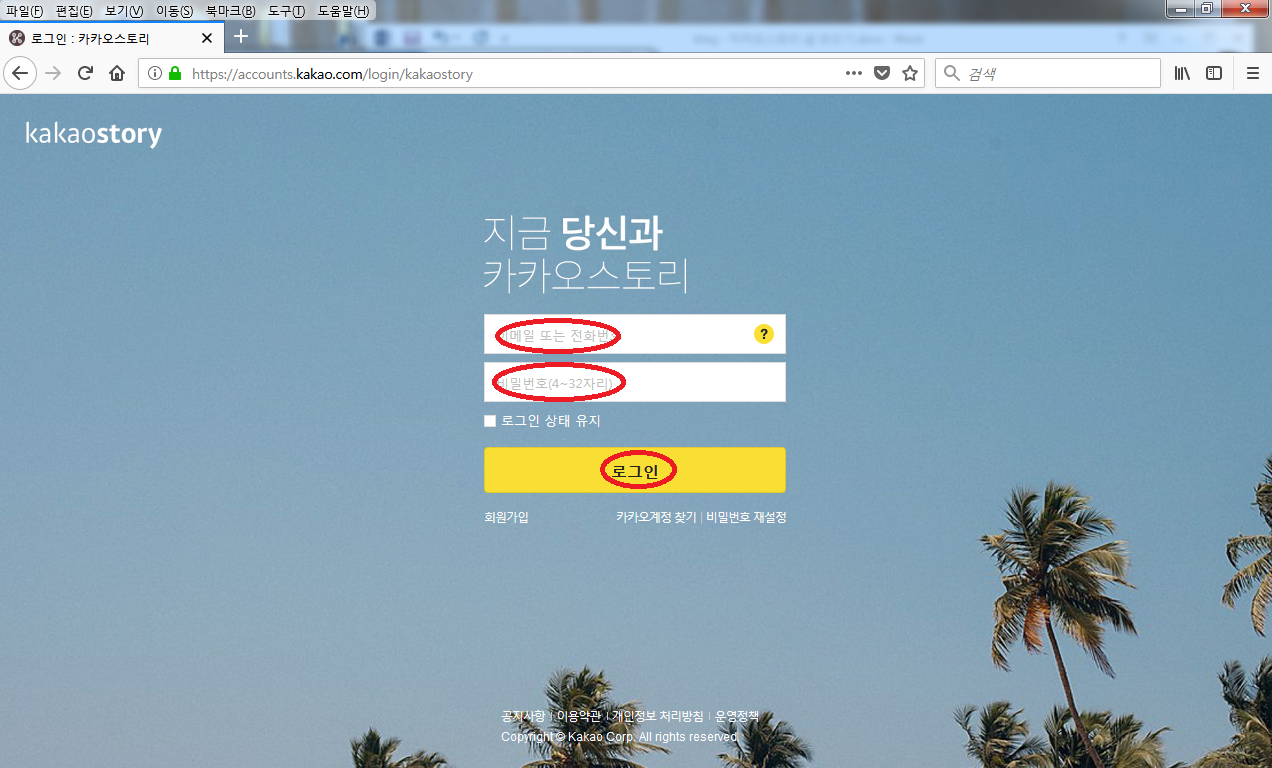
그러면 웹 브라우저 ‘소스 보기’
기능을 이용하여 로그인 중심의 요소를 찾습니다.
아이디와 비밀번호는 <form> 태그를 통해서 서버로 넘어가는데
form 태그 안에 <input>으로 받은 여러 태그가 있어
헷갈리게 합니다.

일단 아이디와 비밀번호외 다른 태그는
무시하고 아이디와 비밀번호만 사용하려고 합니다. “id=loginEmail”로 아이디 입력으로 보이는 라인 997를 찾고 “type=password”로 비밀번호 입력으로 보이는 라인1013를 찾습니다. 아이디는 form 다음에 나오는 태그로 따지면 <form> <fieldset> <div>
<input> 순입니다.

라인 1038에는
로그인 버튼도 있습니다.

로그인에는 아래 selenium 프로그램을 이용합니다. 로그인하고 https://story.kakao.com/mudbull
로 이동하는 것까지 프로그램에 넣도록 합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | # -*- coding: utf-8 -*- from selenium import webdriver driver = webdriver.Firefox() # geckodriver in the same directory with this script driver.implicitly_wait(3) driver.get('https://accounts.kakao.com/login/kakaostory') driver.find_element_by_xpath("//form/fieldset/div/input[@name='email']").send_keys('yooXXXXX@gmail.com') driver.find_element_by_xpath("//form/fieldset/div/input[@name='password']").send_keys('XXXXXXXXXXXX') btn = driver.find_element_by_xpath("//button[text()='로그인']") btn.click() driver.get('https://story.kakao.com/mudbull') |
라인4에서 firefox
웹 브라우저를 띄웁니다. 이 프로그램과 같은 디렉토리에 geckodriver.exe가 있어야 웹 브러우저가 뜹니다. 라인5에서 웹 브라우저가
준비될 때까지 3초를 기다리고 라인6에서 로그인 화면에 접속합니다. 라인 8과 9는 각각 아이디와 비밀번호를 가리키는 element를 찾아와서 send_keys() 함수로 값을 부여하는 과정입니다.
element를 찾을 때는 find_element_by_xpath() 함수를 사용하는데
인수를 지정해서 element를 찾습니다. 라인8에서 사용된 인수는 "//form/fieldset/div/input[@name='email']"로 form -> fieldset -> div ->
input 태그를 찾는데 input
태그는 attribute name이 ‘email’이어야 함을 뜻합니다. form 앞에 “//” 두번은
form 태그 전에는 어떤 것이 와도 괜찮다는 의미입니다. 라인 11에는 로그인
button를 찾은 함수가 있는데
“//button[text()='로그인']” 는 button
태그 중에 text가 ‘로그인’인 것을 찾습니다. 이와
비슷하게 라인 8에 나온 "//form/fieldset/div/input[@name='email']"도 더 줄여서 “//input[@name=’email’]”도 가능할 것 같습니다.
라인 12는 button를 클릭하다는 의미이고 라인 14는 페이지를 'https://story.kakao.com/mudbull' 로 이동합니다.
form 태그 안에 로그인 정보에 다른 여러
element가 있었는데 무시했었는데 로그인하는데에는 지장이 없습니다.
selenium 프로그램으로 자동 로그인까지는
성공해서 웹 브라우저에서는 글을 볼 수 있습니다. 아래 노란색 선 안의 글들을 모으려고 하는데 이 글들은
소스 보기에도 나오지 않고 SPA의 웹 크롤링 (https://blog.naver.com/yoojchul/221333353523)을 시도해도 글을 찾을 수가 없습니다. 카카오스토리는 backbone과 비슷한 자체 framework을 사용한다고 합니다.

그런데 웹 브라우저에서 F12를 눌러
나오는 디버깅 화면을 보니 “GET”으로 그림 뿐만 아니라 json 파일을 가져 오는 것을 알 수 있습니다.

오른쪽 하단 화면을 더 키우면 자세한
내용이 나오는데 특히 “응답” 탭에서 찾고 있는 글이 여기에 있었습니다.

“헤더” 탭을 보면 URL까지 나옵니다. 이 URL로 글들만
서버로부터 json 파일 형식으로 받아 오고 있었습니다.

그래서 아래와 같은 파이썬 프로그램으로
한 페이지안에 들어 있는 글들의 집합을 json으로 저장합니다. json 형식을 바로 디코딩할 수도 있지만 이 페이지의 경우
json으로 디코딩해서 출력을 시도하면
hang이 되거나 Unicode exception이 발생해서 디코딩을 다음 기회로
미룹니다. 아마도 예상하지 못한 문자가
있어 이런 문제를 야기하는 것 같습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | # -*- coding: utf-8 -*- import urllib.request import json import gzip url = 'https://story.kakao.com/a/profiles/mudbull/activities?ag=false&since=&_=153396578026143' hdr = {'Accept' : 'application/json'.encode('utf-8'), 'Accept-Encoding' : 'gzip, deflate, br'.encode('utf-8'), 'Accept-Language' : 'ko'.encode('utf-8'), 'Connection' : 'keep-alive', 'Cookie' : '_kadu=fr6-ASmuoqGhJFsG_1533960…6978; kuid=470960945171005441'.encode('utf-8'), 'Host ' : 'story.kakao.com'.encode('utf-8'), 'Referer' : 'https://story.kakao.com/mudbull'.encode('utf-8'), 'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; W…) Gecko/20100101 Firefox/61.0'.encode('utf-8'), 'X-Kakao-ApiLevel' : '45'.encode('utf-8'), 'X-Kakao-DeviceInfo' : 'web:d;-;-'.encode('utf-8'), 'X-Kakao-VC' : '4da14561d321f651ae6f'.encode('utf-8'), 'X-Requested-With' : 'XMLHttpRequest'.encode('utf-8')} req = urllib.request.Request(url, headers=hdr) resp = urllib.request.urlopen(req) print(resp.info()) filedata = gzip.decompress(resp.read()) with open("data.txt", 'wb') as f: f.write(filedata) f.close() |
글을 가져 올 때는 url 정보외에
header 정보도 필요합니다. 라인 8에서
19에 나온 header 정보는 디버깅 화면에서 확인된 “요청 해더”를 그대로
사용합니다. zip으로 압축된 형식으로
서버에서 보내 주기 때문에 라인 24에서 gzip.decompress()로 푸는 함수가 필요합니다.







